论文分享:基于注意力机制的 trace 采样算法
背景
traces 是现代分布式可观测领域一类重要的数据类型。服务在运行过程中很容易产生数量极多的 traces 数据,因此,对于它的采样也成了一个重要的话题。
最传统的采样方式是头采样,它通常基于概率随机,通过 context 往下传递避免 traces 断裂。或者基于单个 span 上一些简单的特征,但是这样往往会导致 span 断开。而尾采样能在一定程度上解决这些问题,目前在各种解决方案中也较常见。尾采样可以用上 trace 级别的特征,因此常见 “trace 中有 error span 就一定保留” 这样的规则。但是大部分的尾采样系统更关注单个 trace 级别的信息,而没有对多个 traces 做比较,去更好地保留那些“不常见”的 traces。
以 Datadog retention filter 为例,它在数据进入热库 15 分钟后,写入冷库前做过滤和采样,此时通常有完整的 traces 信息。它支持保留含 error 的,也支持保证服务、接口等相关字段的唯一组合至少保留一个。
无论是随机性高的头采样,还是传统的尾采样,对“罕见” traces 都缺乏足够的判断能力。“罕见” traces 很可能因为本身基数小,被全部丢弃。像 Datadog 做了基于服务、接口名称等基本信息的“罕见” span 采样,算是考虑到了这个方向,但做的很浅。
今天分享的这篇论文,名为 《Sieve: Attention-based Sampling of End-to-End Trace Data in Distributed Microservice Systems》,提出了一种采样算法,它在分析 traces 独特性上做了一些努力,更容易分析出 “罕见” 的 traces,这种保留“罕见”span 的采样在论文里被称为偏置采样(biased sampling)。
基本思路
分析 “罕见” 的服务行为并不是一个新的议题。早在 2004 年,就有一篇基于描述基于路径去做故障和演进管理的文章:Path-Based Failure and Evolution Management。
在 tracing 的概念逐渐普及后,这种基于路径结构去分析 traces 的方式也一直有人在研究。
这个“路径结构”的不同很好理解:比如有一个场景,正常的调用是 A→B→C→D 四个 span,但是某种情况命中一个特殊的条件,使路径变成了 A→B→C→E,那么这条 trace 就是非常独特、不常见的。从采样的角度讲,这种 trace 应该保留。
另一个常见的方式是基于延迟。它在可观测领域更加常见,APM 系统几乎都会提供功能,去查看延迟明显高于其他同类的那些 span。这些延迟高于同类的 trace、span 显然也是不常见的、应该保留的。
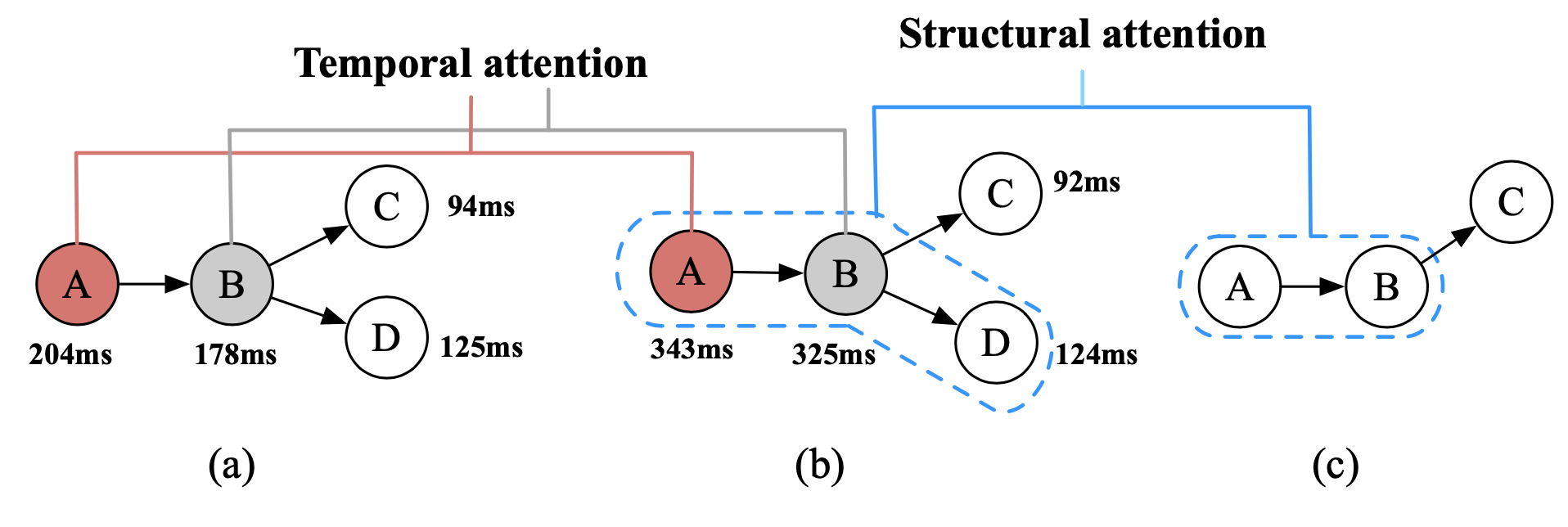
以上图为例,a 与 b 之间是延迟(论文里用了“时间性”)的差异;b 与 c 之间则是结构的差异。
基于路径结构和延迟的采样之前都有人研究过,但没有把它们放一起。只有它们之中的一个,会有一定的局限性,比如有一个基于 MySQL 数据库 + Redis 的业务服务,它有两种常见情况:
- 命中了 Redis 缓存,没调用 MySQL,延迟较低。
- 没命中 Redis 环境,调用了 MySQL,延迟较高。
这两种情况都是正常的、预期中的。而如果出现一种情况是“没调用 MySQL,延迟较高”,则它是异常的。单纯基于路径结构或者延迟不能分析出这种特殊性。
论文的作者设计了把两者结合,基于注意力机制,设计了一个这样的采样系统,它会同时基于 traces 的路径结构和 span 延迟信息(原文直译为结构性和时间性)去做采样决策。
系统设计
为了开发一个这样的在线采样器,它需要解决以下几个问题:
-
trace 的表示。trace 的结构本身是为了给人类看的,这里需要把它编码成算法能处理的形式。
- 注:作者发布论文时还没有 GPT,并且用 GPT 去编码所有 trace 数据,开销上也不划算,可能不如全部保存。)
-
有注意力的偏置采样。需要用注意力机制去尽量保留那些不常见的 span。
-
恒定的空间、时间复杂度。需要保证采样的速度和资源消耗。

如上是 sieve21 采样器的整体设计。可以看到它有三个核心组件构成:
- Encoder,编码器
- Scorer,打分器
- Sampler,采样器
出于篇幅考虑,这里不细说它们的具体实现,只做简单的思路介绍。
编码器
编码器是把 traces 编码成向量。
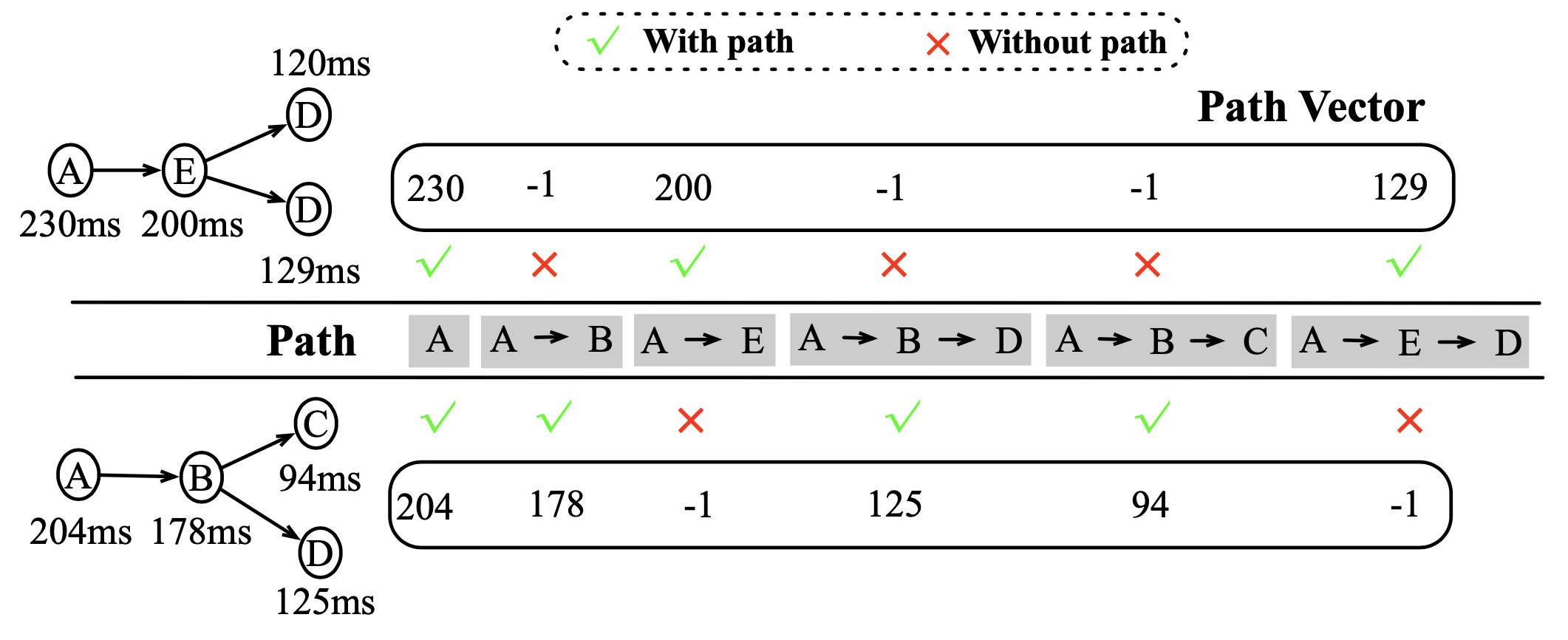
它的思路是从 root span 开始遍历,每到一个 span,就把 root span 到它作为一条路径 pi,然后每条路径尾部 span 上的延迟就构成了一个向量。每个 span 都产生这样一个向量,如果它缺少了某几条路径,则这些路径上取值为 -1。这样这个向量就能反应对应 trace 的结构和时间特征。
打分器
打分器的作用是打分,分数反映每个 trace 被保留的概率。
它包括三个部分:
隔离
隔离,或者说切割,指的是把那些与众不同的向量给隔离出来。它使用了一个名为 RRCF(Robust Random Cut Forest,稳健随机采伐森林)的模型。它基于“孤立森林” ——一种用于在样本空间内找到那些稀疏的、容易被“孤立”的点的机器学习算法,针对流式数据做了改进。
这里不展开说明,有兴趣的同学可以阅读这篇博客。
注意力打分
在 RRCF 的算法中,罕见的向量在被切割后,会有更短的路径。根据这一点,这里会基于路径长度给向量打分。
降维
随着算法的持续运行,随机罕见情况不断产生,路径越来越多,则向量的维度也会越来越大,最终超过这个系统的负载。因此需要一个降维的流程来抵消这一影响。
它会删除在 RRCF 算法中无效的维度。也会删除没有被用于切割,且值的方差小于 0.1 的维度。
采样器
采样器则是基于打分的结构进行采样。
它会设置一个滑动窗口,保存最近 $k$ 个 traces 的分数 $s_1 … s_k$。对于新来的一个分数 $s_{k+1}$,会把它与原来的 k 个分数一起计算一个方差 $var_{k+1}$,再和原来 $k$ 个分数的方差 $var_k$ 做比较。如果 $var_{k+1}$ 和 $var_k$ 的差距超过了一个设置的阈值,就会用一个指数级的函数去计算一个通常很接近 1 的概率,即这个 span 大概率会被留下来。否则正常情况下,采样率为 $\frac{s_{k+1}}{\sum^{k+1}_{i=1} s_i}$。
这样就保证了那些罕见程度明显不同的 trace 被大概率保留。其他的 traces 则是按概率采样,且采样率和它的注意力得分成正比。
将上面几个组件,按照本节开头的图串联起来,就构成了整个采样系统。
评估
在论文中,作者基于来自 VWR、AIOps、Boutique、TC 的四个数据集,从偏差抽样、敏感性、效果、获取代表性样本的能力、开销五个方面对 sieve21 进行了评估。
偏差抽样
在偏差抽样方面,取了两组数据,每组共 1000 条 trace。第一组有 10 条 traces 的延迟偏离了正态分布,其余正常。第二组有 10 条 traces 具有不常见的结构。
- 第一组异常 traces 的采样概率为 0.999,常规 traces 为 0.019,1 个误报。误报原因是选择了次优阈值。这在实际应用中只会增加少量样本,对整体结果影响不大。
- 第二组异常 traces 采样率 0.996,常规 0.020,2 个误报。误报的 traces 的延迟过低,偏离了整体延迟分布。因此这也是说得通的。
总之,偏差抽样上表现良好。
敏感性
在敏感性方面,它在 990 个常规随机分布 traces 的基础上,增加了 5 条延迟稍高的 traces、2 条结构轻微差异(只多了一个 span)的 traces、3 条少了很多 span 的 traces。如下表:
| type | spans | latency | amount |
|---|---|---|---|
| common | 58 | 0-300ms | 990 |
| uncommon | 58 | >400ms | 5 |
| 59 | 0-300ms | 2 | |
| 7 | 0-300ms | 3 |
最后一步采样中的阈值对这个结果有影响,阈值越低则越敏感,同时假阳性的增加幅度并不高。故作者建议调低阈值,通过少量增加 FP,来获取更高的 TP。
效果
作者将 sieve21 与 HC(hierarch clustering,分层聚类,这种算法能判断结构上的罕见,但判断不了延迟上的罕见) 算法、随机采样做比较。结果发现,除了在数据集大小为 10的测试中,Sieve21 弱于 HC,后面随着数据集大小增加,Sieve21 的采样表现快速上升,逐渐遥遥领先。
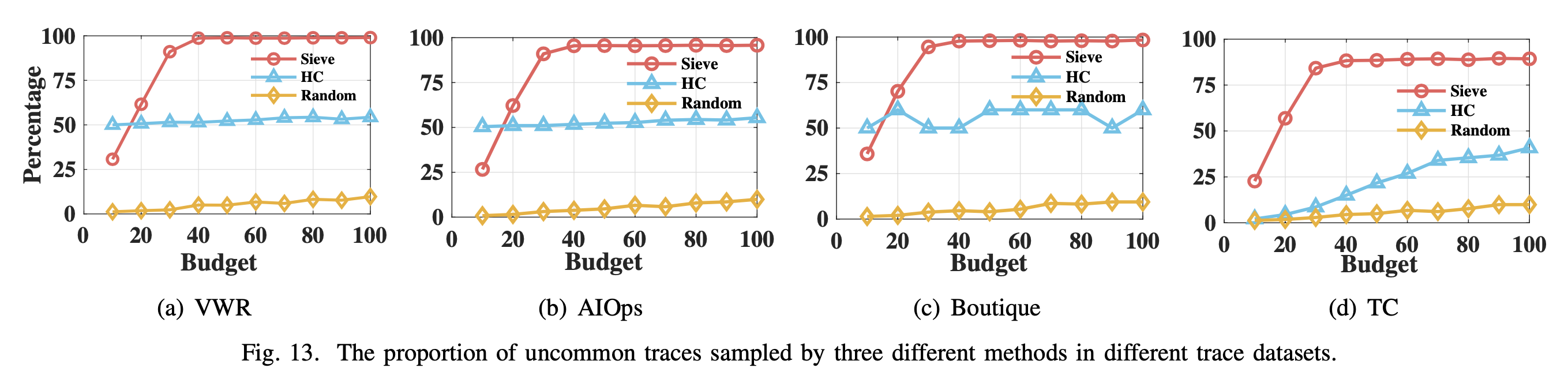
获取代表性样本的能力
作者对它和 HC 做了获取代表性样本的能力对比。作者通过一个大小为 6561 的样本集,比较留下来的 traces。结果发现,sieve 能留下更多的罕见 span,同时丢掉很多的常见 span,保留的 span 总数也更低。
开销
作者在设置 RRCT 数量为 20 的条件下,对采样过程做了延迟统计。结果延迟都在 3 ~ 33ms 之间,即使是含有数百个 span 的 trace,也能很好地处理。
个人评价
首先,基于的结构采样和分析,是我之前学习和可观测相关的东西时忽略了的一个方向。从这篇论文来说,感觉这个方向可以做的东西非常多,应用的潜力也很大。
从工程实践上来说,论文里采用模拟数据集,这样大部分 traces 都是完整的,及时上报的。如果有 span 延迟太大,过采样器时还没采集到,或者采集链路上被丢弃了,则按照这个算法,它很容易被认为具有罕见的结构,从而被保留。
另外,测试集里的样本里,common 组里的 span 数量都是恒定的。而在真实的业务服务中,常常会有循环调用 db 之类的行为,导致每条 trace 的 span 数量都不一样,从而被认为是具有不一样的结构性特征。
从上面两个角度,这个算法直接用于真实的数据可能会有一些 gap。 但是它是一个很好的、具有潜力的方向,值得我们持续关注。