論文分享:基於注意力機制的 trace 採樣算法
背景
traces 是現代分佈式可觀測領域一類重要的數據類型。服務在運行過程中很容易產生數量極多的 traces 數據,因此,對於它的採樣也成了一個重要的話題。
最傳統的採樣方式是頭採樣,它通常基於概率隨機,通過 context 往下傳遞避免 traces 斷裂。或者基於單個 span 上一些簡單的特徵,但是這樣往往會導致 span 斷開。而尾採樣能在一定程度上解決這些問題,目前在各種解決方案中也較常見。尾採樣可以用上 trace 級別的特徵,因此常見 “trace 中有 error span 就一定保留” 這樣的規則。但是大部分的尾採樣系統更關注單個 trace 級別的信息,而沒有對多個 traces 做比較,去更好地保留那些“不常見”的 traces。
以 Datadog retention filter 爲例,它在數據進入熱庫 15 分鐘後,寫入冷庫前做過濾和採樣,此時通常有完整的 traces 信息。它支持保留含 error 的,也支持保證服務、接口等相關字段的唯一組合至少保留一個。
無論是隨機性高的頭採樣,還是傳統的尾採樣,對“罕見” traces 都缺乏足夠的判斷能力。“罕見” traces 很可能因爲本身基數小,被全部丟棄。像 Datadog 做了基於服務、接口名稱等基本信息的“罕見” span 採樣,算是考慮到了這個方向,但做的很淺。
今天分享的這篇論文,名爲 《Sieve: Attention-based Sampling of End-to-End Trace Data in Distributed Microservice Systems》,提出了一種採樣算法,它在分析 traces 獨特性上做了一些努力,更容易分析出 “罕見” 的 traces,這種保留“罕見”span 的採樣在論文裏被稱爲偏置採樣(biased sampling)。
基本思路
分析 “罕見” 的服務行爲並不是一個新的議題。早在 2004 年,就有一篇基於描述基於路徑去做故障和演進管理的文章:Path-Based Failure and Evolution Management。
在 tracing 的概念逐漸普及後,這種基於路徑結構去分析 traces 的方式也一直有人在研究。
這個“路徑結構”的不同很好理解:比如有一個場景,正常的調用是 A→B→C→D 四個 span,但是某種情況命中一個特殊的條件,使路徑變成了 A→B→C→E,那麼這條 trace 就是非常獨特、不常見的。從採樣的角度講,這種 trace 應該保留。
另一個常見的方式是基於延遲。它在可觀測領域更加常見,APM 系統幾乎都會提供功能,去查看延遲明顯高於其他同類的那些 span。這些延遲高於同類的 trace、span 顯然也是不常見的、應該保留的。
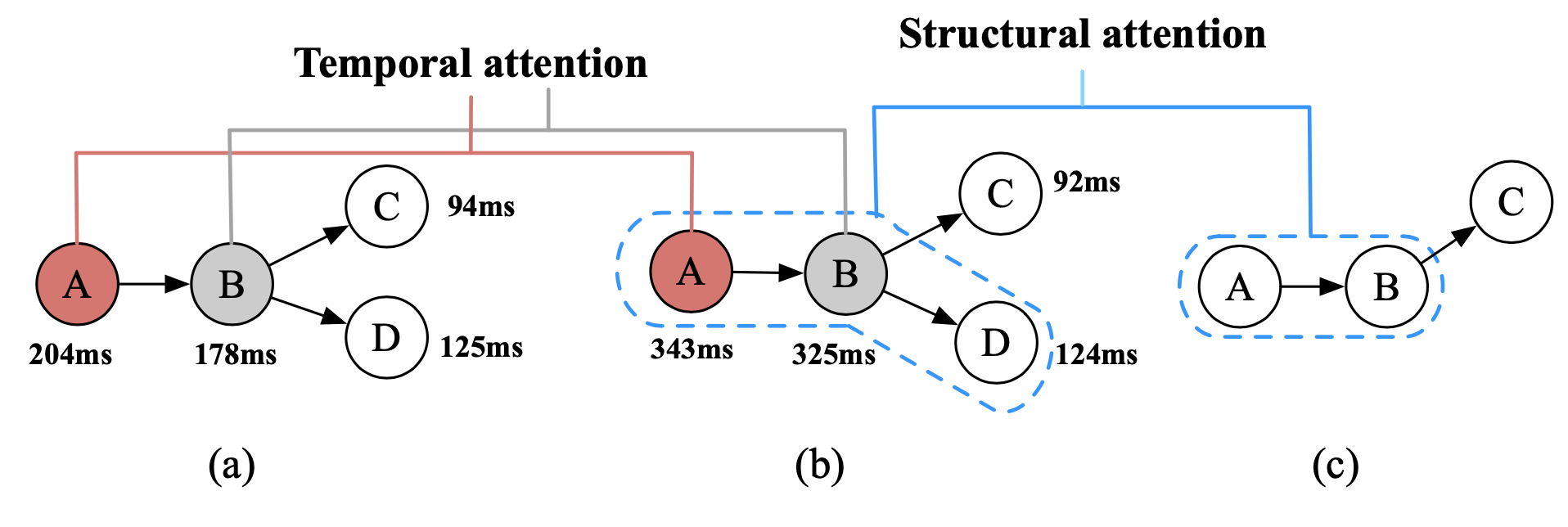
以上圖爲例,a 與 b 之間是延遲(論文裏用了“時間性”)的差異;b 與 c 之間則是結構的差異。
基於路徑結構和延遲的採樣之前都有人研究過,但沒有把它們放一起。只有它們之中的一個,會有一定的侷限性,比如有一個基於 MySQL 數據庫 + Redis 的業務服務,它有兩種常見情況:
- 命中了 Redis 緩存,沒調用 MySQL,延遲較低。
- 沒命中 Redis 環境,調用了 MySQL,延遲較高。
這兩種情況都是正常的、預期中的。而如果出現一種情況是“沒調用 MySQL,延遲較高”,則它是異常的。單純基於路徑結構或者延遲不能分析出這種特殊性。
論文的作者設計了把兩者結合,基於注意力機制,設計了一個這樣的採樣系統,它會同時基於 traces 的路徑結構和 span 延遲信息(原文直譯爲結構性和時間性)去做採樣決策。
系統設計
爲了開發一個這樣的在線採樣器,它需要解決以下幾個問題:
-
trace 的表示。trace 的結構本身是爲了給人類看的,這裏需要把它編碼成算法能處理的形式。
- 注:作者發佈論文時還沒有 GPT,並且用 GPT 去編碼所有 trace 數據,開銷上也不划算,可能不如全部保存。)
-
有注意力的偏置採樣。需要用注意力機制去儘量保留那些不常見的 span。
-
恆定的空間、時間複雜度。需要保證採樣的速度和資源消耗。

如上是 sieve21 採樣器的整體設計。可以看到它有三個核心組件構成:
- Encoder,編碼器
- Scorer,打分器
- Sampler,採樣器
出於篇幅考慮,這裏不細說它們的具體實現,只做簡單的思路介紹。
編碼器
編碼器是把 traces 編碼成向量。
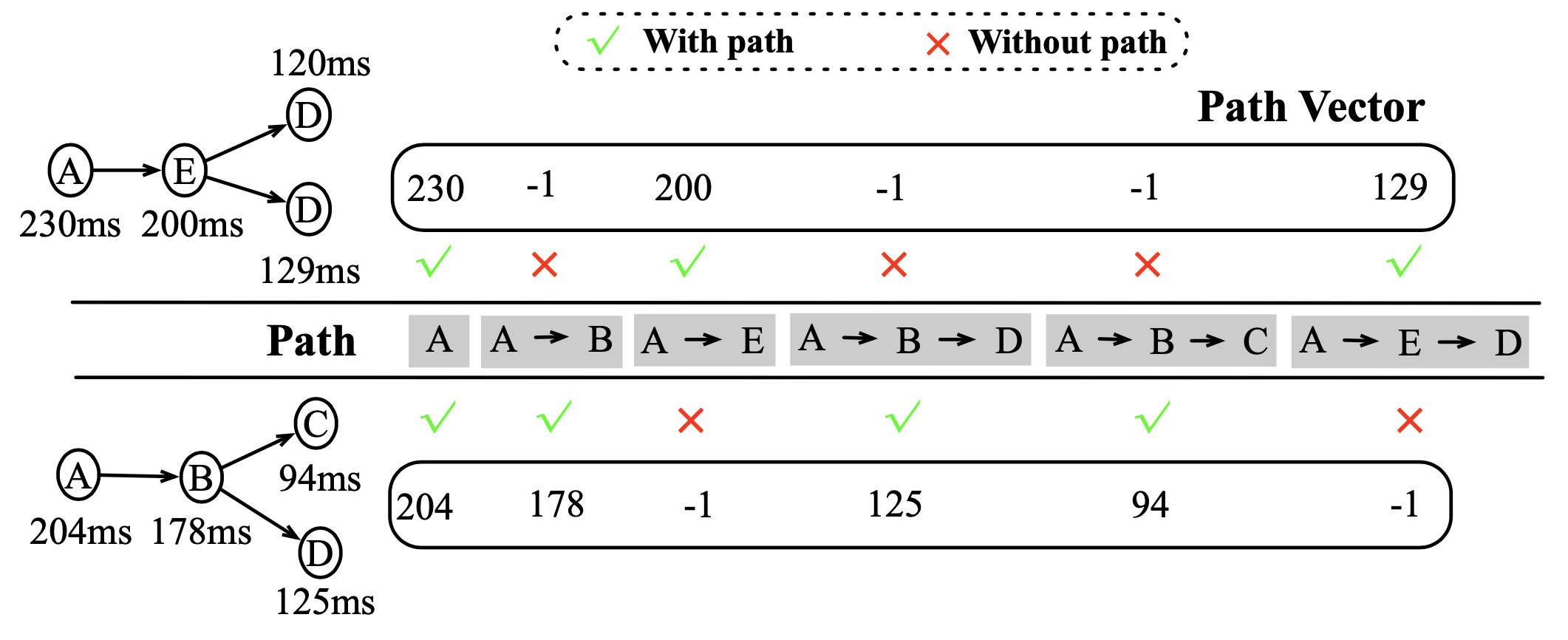
它的思路是從 root span 開始遍歷,每到一個 span,就把 root span 到它作爲一條路徑 pi,然後每條路徑尾部 span 上的延遲就構成了一個向量。每個 span 都產生這樣一個向量,如果它缺少了某幾條路徑,則這些路徑上取值爲 -1。這樣這個向量就能反應對應 trace 的結構和時間特徵。
打分器
打分器的作用是打分,分數反映每個 trace 被保留的概率。
它包括三個部分:
隔離
隔離,或者說切割,指的是把那些與衆不同的向量給隔離出來。它使用了一個名爲 RRCF(Robust Random Cut Forest,穩健隨機採伐森林)的模型。它基於“孤立森林” ——一種用於在樣本空間內找到那些稀疏的、容易被“孤立”的點的機器學習算法,針對流式數據做了改進。
這裏不展開說明,有興趣的同學可以閱讀這篇博客。
注意力打分
在 RRCF 的算法中,罕見的向量在被切割後,會有更短的路徑。根據這一點,這裏會基於路徑長度給向量打分。
降維
隨着算法的持續運行,隨機罕見情況不斷產生,路徑越來越多,則向量的維度也會越來越大,最終超過這個系統的負載。因此需要一個降維的流程來抵消這一影響。
它會刪除在 RRCF 算法中無效的維度。也會刪除沒有被用於切割,且值的方差小於 0.1 的維度。
採樣器
採樣器則是基於打分的結構進行採樣。
它會設置一個滑動窗口,保存最近 $k$ 個 traces 的分數 $s_1 … s_k$。對於新來的一個分數 $s_{k+1}$,會把它與原來的 k 個分數一起計算一個方差 $var_{k+1}$,再和原來 $k$ 個分數的方差 $var_k$ 做比較。如果 $var_{k+1}$ 和 $var_k$ 的差距超過了一個設置的閾值,就會用一個指數級的函數去計算一個通常很接近 1 的概率,即這個 span 大概率會被留下來。否則正常情況下,採樣率爲 $\frac{s_{k+1}}{\sum^{k+1}_{i=1} s_i}$。
這樣就保證了那些罕見程度明顯不同的 trace 被大概率保留。其他的 traces 則是按概率採樣,且採樣率和它的注意力得分成正比。
將上面幾個組件,按照本節開頭的圖串聯起來,就構成了整個採樣系統。
評估
在論文中,作者基於來自 VWR、AIOps、Boutique、TC 的四個數據集,從偏差抽樣、敏感性、效果、獲取代表性樣本的能力、開銷五個方面對 sieve21 進行了評估。
偏差抽樣
在偏差抽樣方面,取了兩組數據,每組共 1000 條 trace。第一組有 10 條 traces 的延遲偏離了正態分佈,其餘正常。第二組有 10 條 traces 具有不常見的結構。
- 第一組異常 traces 的採樣概率爲 0.999,常規 traces 爲 0.019,1 個誤報。誤報原因是選擇了次優閾值。這在實際應用中只會增加少量樣本,對整體結果影響不大。
- 第二組異常 traces 採樣率 0.996,常規 0.020,2 個誤報。誤報的 traces 的延遲過低,偏離了整體延遲分佈。因此這也是說得通的。
總之,偏差抽樣上表現良好。
敏感性
在敏感性方面,它在 990 個常規隨機分佈 traces 的基礎上,增加了 5 條延遲稍高的 traces、2 條結構輕微差異(只多了一個 span)的 traces、3 條少了很多 span 的 traces。如下表:
| type | spans | latency | amount |
|---|---|---|---|
| common | 58 | 0-300ms | 990 |
| uncommon | 58 | >400ms | 5 |
| 59 | 0-300ms | 2 | |
| 7 | 0-300ms | 3 |
最後一步採樣中的閾值對這個結果有影響,閾值越低則越敏感,同時假陽性的增加幅度並不高。故作者建議調低閾值,通過少量增加 FP,來獲取更高的 TP。
效果
作者將 sieve21 與 HC(hierarch clustering,分層聚類,這種算法能判斷結構上的罕見,但判斷不了延遲上的罕見) 算法、隨機採樣做比較。結果發現,除了在數據集大小爲 10的測試中,Sieve21 弱於 HC,後面隨着數據集大小增加,Sieve21 的採樣表現快速上升,逐漸遙遙領先。
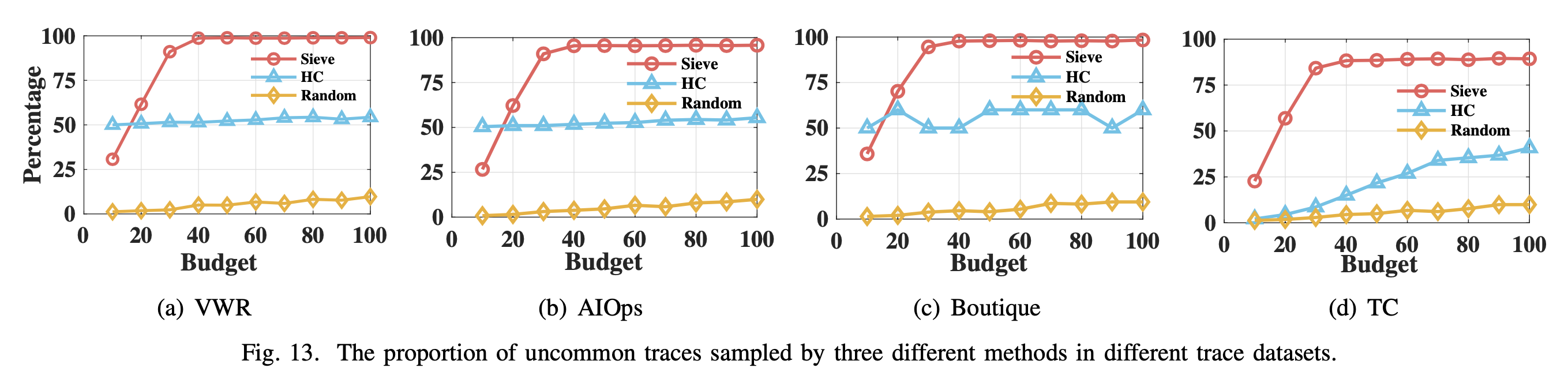
獲取代表性樣本的能力
作者對它和 HC 做了獲取代表性樣本的能力對比。作者通過一個大小爲 6561 的樣本集,比較留下來的 traces。結果發現,sieve 能留下更多的罕見 span,同時丟掉很多的常見 span,保留的 span 總數也更低。
開銷
作者在設置 RRCT 數量爲 20 的條件下,對採樣過程做了延遲統計。結果延遲都在 3 ~ 33ms 之間,即使是含有數百個 span 的 trace,也能很好地處理。
個人評價
首先,基於的結構採樣和分析,是我之前學習和可觀測相關的東西時忽略了的一個方向。從這篇論文來說,感覺這個方向可以做的東西非常多,應用的潛力也很大。
從工程實踐上來說,論文裏採用模擬數據集,這樣大部分 traces 都是完整的,及時上報的。如果有 span 延遲太大,過採樣器時還沒采集到,或者採集鏈路上被丟棄了,則按照這個算法,它很容易被認爲具有罕見的結構,從而被保留。
另外,測試集裏的樣本里,common 組裏的 span 數量都是恆定的。而在真實的業務服務中,常常會有循環調用 db 之類的行爲,導致每條 trace 的 span 數量都不一樣,從而被認爲是具有不一樣的結構性特徵。
從上面兩個角度,這個算法直接用於真實的數據可能會有一些 gap。 但是它是一個很好的、具有潛力的方向,值得我們持續關注。